Product
Introducing Rutter Embedded ERP
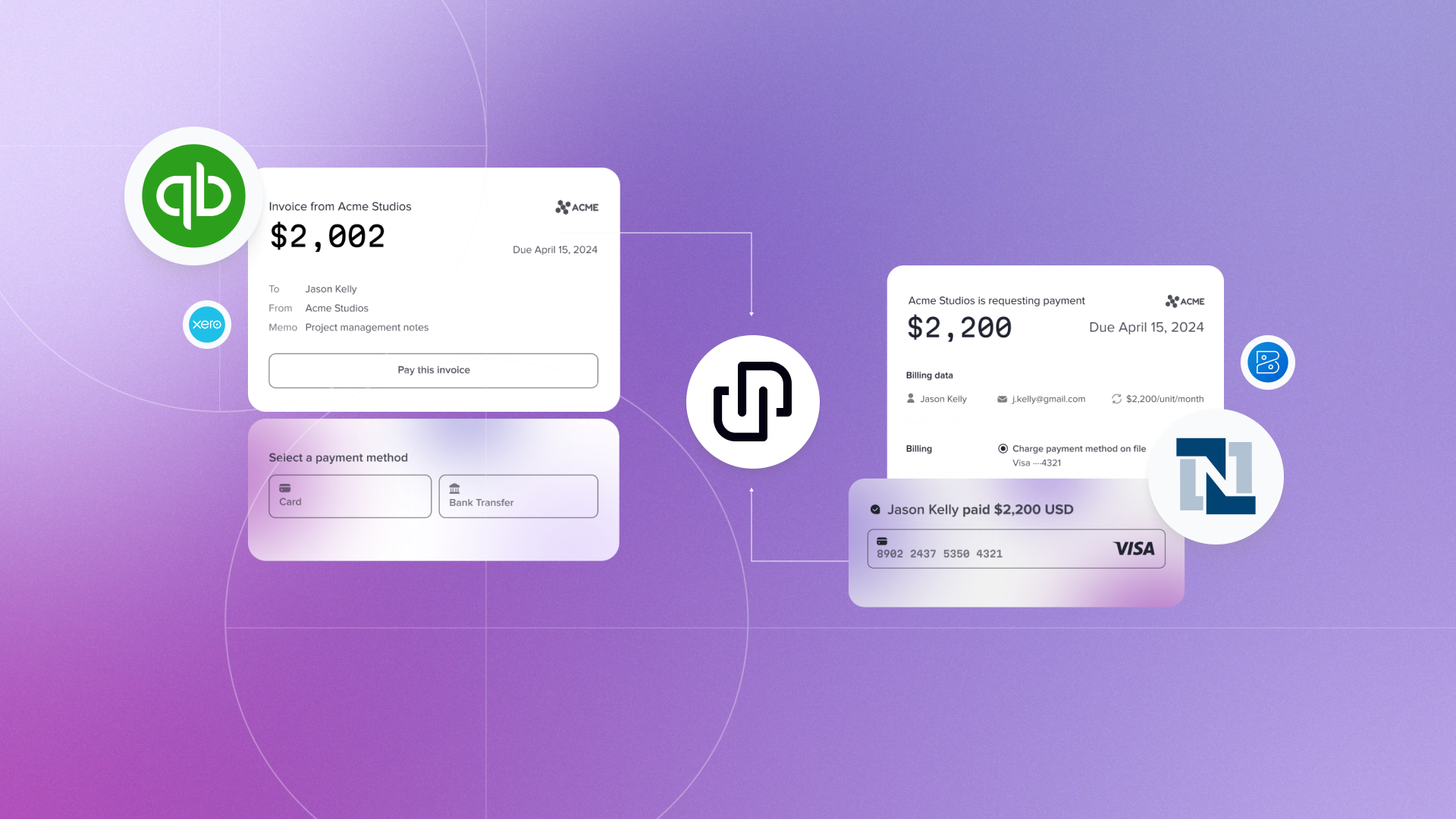
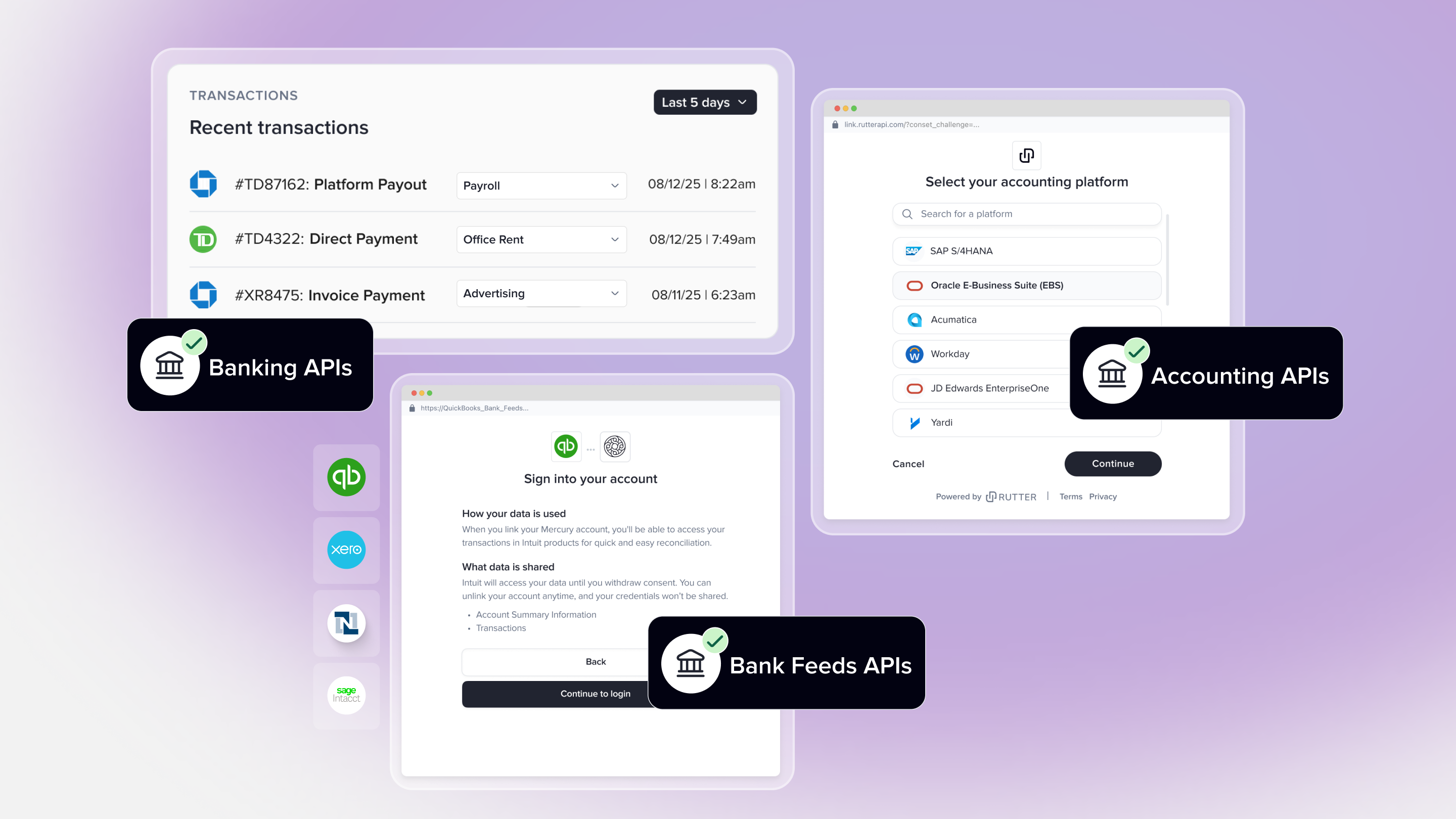
Rutter Embedded ERP is a new way for fintechs and banks to deliver their products as native experiences inside the ERPs their midmarket customers run on.

When we launched Rutter Odyssey in 2022, we set out to make building integrations 10x faster. Three years later, our customers connect to dozens of accounting, commerce, HRIS, and banking platforms through a single Rutter API. Odyssey did its job: it turned a brand-new platform integration into a configuration exercise rather than a months-long project. As LLMs got dramatically better at reading code, writing code, and reasoning about API shapes, we asked the obvious question: what if the engineer building the next integration was an AI agent, and the human's job was to review, verify, and ship?
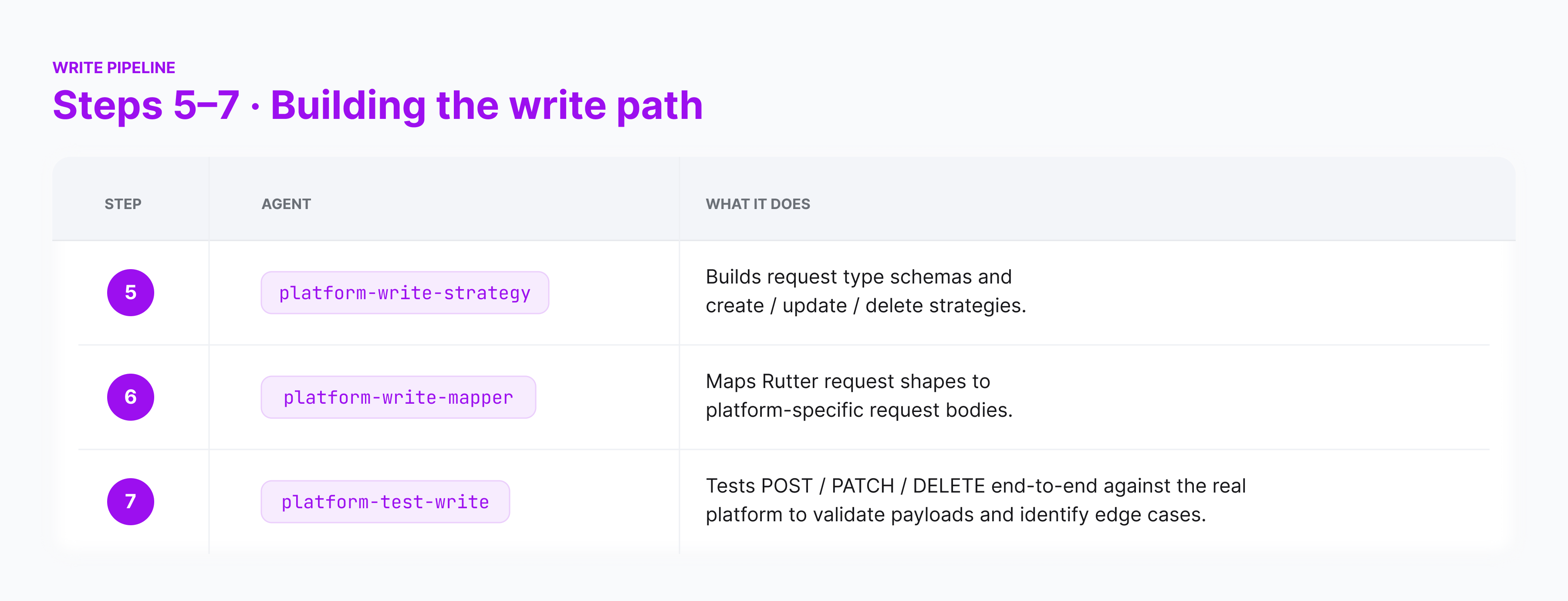
Today, we are sharing how we got there. New platforms, new entities, and new write endpoints at Rutter are now bootstrapped end-to-end by a fleet of specialized AI subagents — agents that write the fetch layer, the schema, the mapper, the tests, and verify the result against a real platform sandbox before a human ever opens the diff.
None of this would work without Odyssey. The architecture we built three years ago is exactly what makes today's AI-driven integration pipeline possible. Skill-less LLMs are not going to build a NetSuite integration. But an LLM aimed at a system with platform nuances, a canonical schema, a deterministic fetch contract, a sync scorecard, and a mapper test framework makes the difference.

Odyssey solved the plumbing. The Fetch Client, Persistence Client, and Refresh Client gave every platform the same skeleton: paginated retrieval, deduped persistence, observable refresh, error recovery. We replaced 85% of the per-platform code with infrastructure.
The remaining 15% turned out to be the hard part. Each new integration still required an engineer to:
Invoice is an Invoice, but every platform has its own opinion on what that means).This is bounded, mechanical work. It is also the kind of work that makes integration engineers either very fast or very burned out. It is the kind of work that an LLM, given the right scaffolding, can do extraordinarily well.
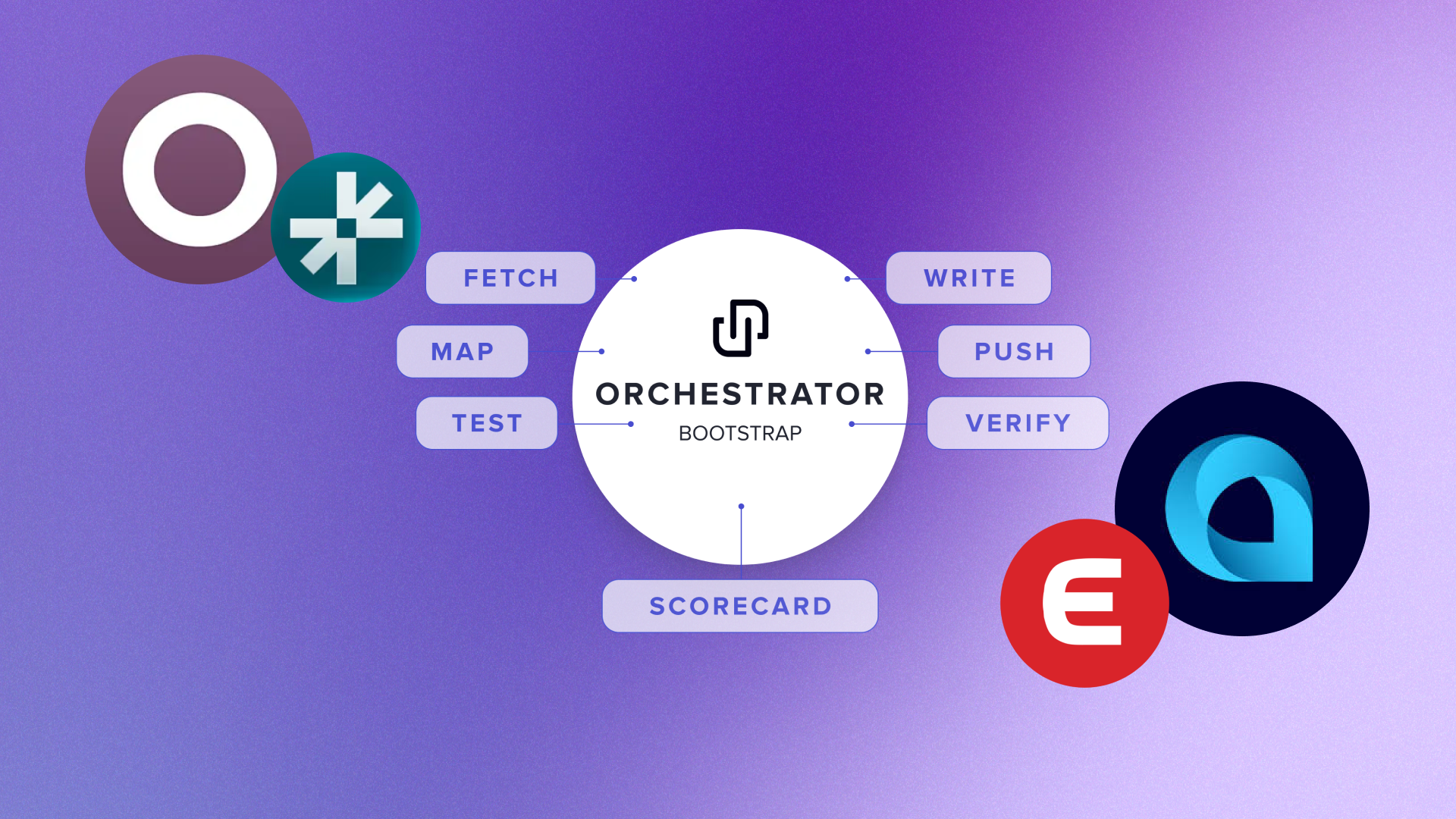
We built a set of specialized subagents inside our development environment. Each agent has a narrowly scoped job, a checklist of inputs, a reference platform to copy from, and a clear definition of done. Together they cover the entire pipeline from "platform we have never heard of" to "live, tested GET and POST endpoints in production."

For brand-new platforms, a top-level platform-bootstrap-first-endpoint agent runs the full pipeline in one go. We provide a link to the platform's API docs, API access, the target Rutter objects, and the auth type. It dispatches the four read subagents in sequence, runs the bootstrap CLI to fetch sample data and infer types, regenerates the sync scorecard, and verifies the first endpoint for an integration end-to-end against a live connection.
Subagents call into a layer of skills — small, scoped command runners that encode our internal workflows so the agent does not have to reinvent them every run. Each one captures a piece of muscle memory that until recently lived only in our integration engineers' heads:
bootstrap-endpoint — scaffolds a brand-new entity from real sample data, pulling a few records from the platform, inferring the data's shape, and generating the typed schemas, scorecards, and test fixtures the rest of our pipeline expects.refresh-item — pulls a real customer connection into a local sandbox and triggers a sync against any platform we support, so the agent can test its work against real platform data rather than mocks or fixtures.db-lookup — inspects connection health and credential state in our database, the same "is this customer's connection alive and authorized?" check our on-call engineers run when something looks off.rutter-api — calls our own Rutter API locally with the right authentication, headers, and force-sync semantics, so the agent can verify what a customer would actually see when they hit the endpoint it just built.push-coverage-pr — runs our full pre-push checklist (typechecking, formatting, regenerating any out-of-date generated files, refreshing the scorecard) and opens a clean pull request ready for human review.These are the same workflows our integration engineers use by hand. Encoding them as skills means the agent inherits institutional knowledge — which commands to run, which environment variables matter, which headers a request needs — and stops getting the boring details wrong.
Plenty of teams have tried pointing an LLM at "build me an integration" and gotten a stack of plausible-looking code that does not run. Odyssey works because it provides us four things that turn out to be exactly what an AI agent needs to ship working code: a canonical schema, a suite of CLI commands to run integration-related operations, a deterministic fetch contract, a scorecard, and a robust integration testing framework.
The single biggest lift Odyssey did was define what an Invoice, a Customer, an Account, an Order actually is at Rutter, independent of any platform. That schema lives in src/platformization/rutter/, and it is the input to every mapper.
For a human, this is a clean abstraction. For an AI agent, it is something more important: it is a specification. The agent does not have to invent a target shape from prose. It reads the schema, reads the platform's response, and produces a typed function from one to the other. That is a problem LLMs are extremely good at — and it is only a tractable problem because the target is fixed.
A suite of CLI commands for integration-related operations — yarn rutter refresh to trigger a sync, yarn rutter item clone to pull a real customer connection into a local sandbox, yarn rutter bootstrap to scaffold a new platform entity, plus generators for types, scorecards, and mapper test cases. The skills below are thin, opinionated wrappers around these commands so the agent uses the right flags every time.
Odyssey's Fetch Client and Persistence Client are deterministic given the same inputs. A TemporalListFetchStrategy configured against Stripe's /customers endpoint will paginate, persist, and dedupe the same way every time. This is what makes our CLI to trigger syncs a reliable signal: if it succeeds and writes rows to the database, the fetch layer is correct.
That gives our test-sync agent something almost no AI coding workflow has: a closed-loop verification step. The agent writes code, runs the refresh, queries the database, and decides for itself whether it succeeded. No human in the loop until the very end.
Every platform in our codebase has a generated scorecard at src/platformization/components/sync/scorecard/scorecards/<PLATFORM>.txt showing which entities sync successfully, which return non-empty data, and which fail. After making any change to a platform's sync/ or fetch/ directory, our agents regenerate the scorecard and diff it against the previous version. If coverage degraded, the agent knows. This was a tool we built to minimize human error, and it turned out to be a valuable feedback loop for an agent.
MapperFactory.registerMapper() is paired with a generated test case suite at __tests__/platformization/platforms/testCases/. Every registered mapper must have a test case, and CI fails if it does not. Our platform-test-mapper agent runs yarn rutter generate-mapper-tests to scaffold cases, then runs them. If the mapper drifts from the schema, the test breaks. If the schema drifts from reality, the scorecard breaks.
This is not theoretical. Over the last few weeks, the Rutter team has aggressively expanded our accounting platform coverage. Eight new or substantially-extended integrations shipped, most of them bootstrapped from zero:
None of this would have been possible at this pace without our integration agents. For each platform, an engineer picked a target entity, handed platform-bootstrap-first-endpoint (or the individual fetch / mapper / test agents for follow-on entities) an item ID and a link to the platform's API docs, and the agent did the mechanical work.
What used to be a multi-week project per platform is now measured in days — and for additional entities on an already-bootstrapped platform, often hours. The bottleneck has shifted: it is no longer "how fast can we write the code," it is "how fast can a human credibly review what the agent produced." That is exactly the bottleneck we want.
There is a temptation to talk about AI-built integrations as a replacement for thoughtful infrastructure. We see the opposite. The teams that will build the most reliable integrations the fastest are the teams that invested in the boring part: canonical schemas, deterministic contracts, observability, and test frameworks that fail loudly. AI agents are a force multiplier on a real platform. They are a lottery ticket on a fragile one.
If you are building a platform of any kind and wondering whether to invest in your internal abstractions or in AI tooling first, our answer is the same as it was in 2022: build the platform. The AI part gets dramatically easier when you do.
Want to see this in action? Get up and running with Rutter.

Building integrated products is hard. We can do that together. Let's chat.